深度学习在深度(视差)估计中的应用(1)

本文对KITTI stereo 2015 datasets 冠军之作Cascade Residual Learning: A Two-stage Convolutional Neural Network for Stereo Matching进行简要解读。
前言
目前深度学习发展的如火如荼,利用CNN可以将图像对的匹配问题看成一个学习问题。但是如何能够得到高质量的深度图像仍然是一个普世问题。本文作者提出了一种新型的层叠式(cascade)CNN结构(CRL:Cascade Residual Learning)去估计深度信息。深度估计的过程大致可以分成两个步骤:
- 在现有的DispNet的基础上添加几个反卷积模块,目的是为了得到full resolution的初始的深度信息,同时能够学习到更多的细节信息;
- 第二步是对第一步中学习到的深度信息进行校准(rectify);这一步利用到了第一步得到的多尺度的深度信息,然后并非是直接学习到优化后的深度信息,而是学习了每个尺度下的深度残差,然后结合第一步中得到的多尺度深度信息合成最终的深度图(这里有点类似于何凯明的residual的思想: It is easier to learn the residual than to learn the disparity directly)。
网络结构
下面详细的介绍下这个网络的结构:
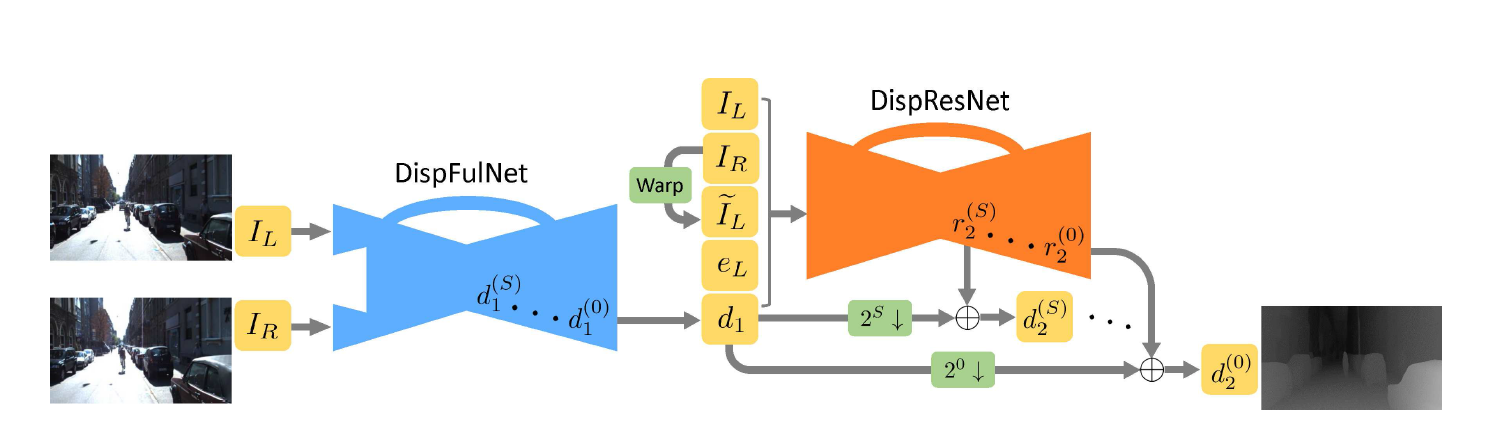
可以很清楚地在上图中看到这两个不同的阶段。对于第一个阶段,类似于文献1中提到的DispNetC结构(C是correlation层的意思),本文作者同样采取了沙漏形的网络结构。但是DispNetC网络的输出图像的分辨率只有原始尺寸的一半!CRL中的DispFulNet在DispNetC的基础上,在最后的两个卷积层增加了添加了反卷积模块,然后再串联左图;通过再次添加一个额外的卷积层,可以使得网络输出为全分辨率(和左右图大小一致)。注意:每个尺度(共6个尺度)上的临时输出与其对应的ground truth之间计算损失。 总结一下就是,这个DispFulNet学习了这样一个网络:通过输入一对图片和,学习到了视差,使得:
上式中的就是把右图根据视差移动后的结果,我们的目标就是越来越接近。
接下来就是第二阶段,将,,,以及串联起来2作为dispResNet的输入。此优化网络最后学到的是多尺度的残差,其中s=0时表示全尺度残差。最后与DispFulNet输出的多尺度深度图做和运算得到最后优化后的深度: 于是就是最后的全尺度输出。
实验结果
以下是对其结果展示: 
Footnotes
-
N. Mayer, E. Ilg, P. Hausser, P. Fischer, D. Cremers, A. Dosovitskiy, and T. Brox. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4040–4048, 2016. ↩
-
E. Ilg, N. Mayer, T. Saikia, M. Keuper, A. Dosovitskiy, and T. Brox. Flownet 2.0: Evolution of optical flow estimation with deep networks. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2462–2470, 2017. ↩