📝笔记:SuperGlue:Learning Feature Matching with Graph Neural Networks论文阅读
ETHZ ASL与Magicleap联名之作,CVPR 2020 Oral(论文见文末),一作是来自ETHZ的实习生,二作是当年CVPR2018 SuperPoint的作者Daniel DeTone。Sarlin小伙之前在MagicLeap实习,在ETHZ(苏黎世联邦理工) ASL 完成硕士,目前在 ETHZ CVG就读博士,不是TUM(慕尼黑工业大学)的CVG。

注:
- SuperPoint参见另外一篇文章《SuperPoint: Self-Supervised Interest Point Detection and Description》,备用链接。
- 后文中反复提到的self-attention/cross-attention,我暂时翻译成自我注意力/交叉注意力。
- 本人知识水平有限,如有错误请在评论区指出。当然,没有问题也可刷刷评论。
下面是一作Daniel DeTone关于SuperPoint的讲解(需要科学上网)。
摘要
本文提出了一种能够同时进行特征匹配以及滤除外点的网络。其中特征匹配是通过求解可微分最优化转移问题( optimal transport problem)来解决;本文基于注意力机制提出了一种将2D特征点以及聚合机制,这使得SuperGlue能够同时感知潜在的3D场景以及进行特征匹配。该算法与传统的,手工设计的特征相比,能够在室内外环境中位姿估计任务中取得最好的结果,该网络能够在GPU上达到实时,预期能够集成到sfm以及slam算法中。
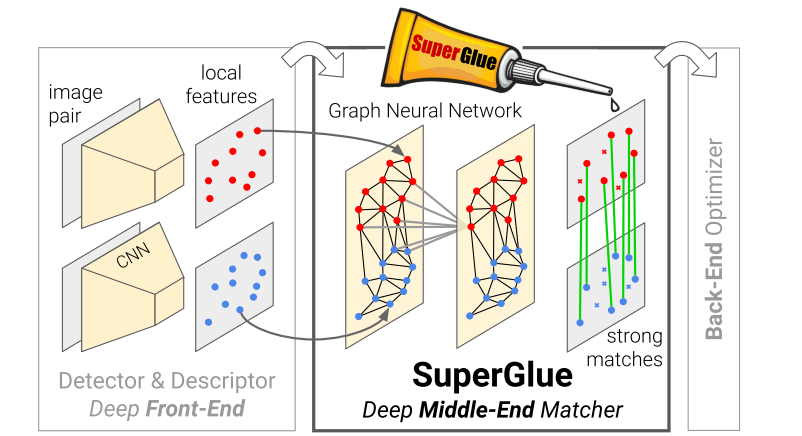
superglue_front
SuperGlue是一种特征匹配网络,它的输入是2张图像中特征点以及描述子(手工特征或者深度学习特征均可),输出是图像特征之间的匹配关系。
作者认为学习特征匹配可以被视为找到两簇点的局部分配关系。作者受到了Transformer的启发,同时将self-和cross-attention利用特征点位置以及其视觉外观进行匹配。
相关工作
局部特征匹配
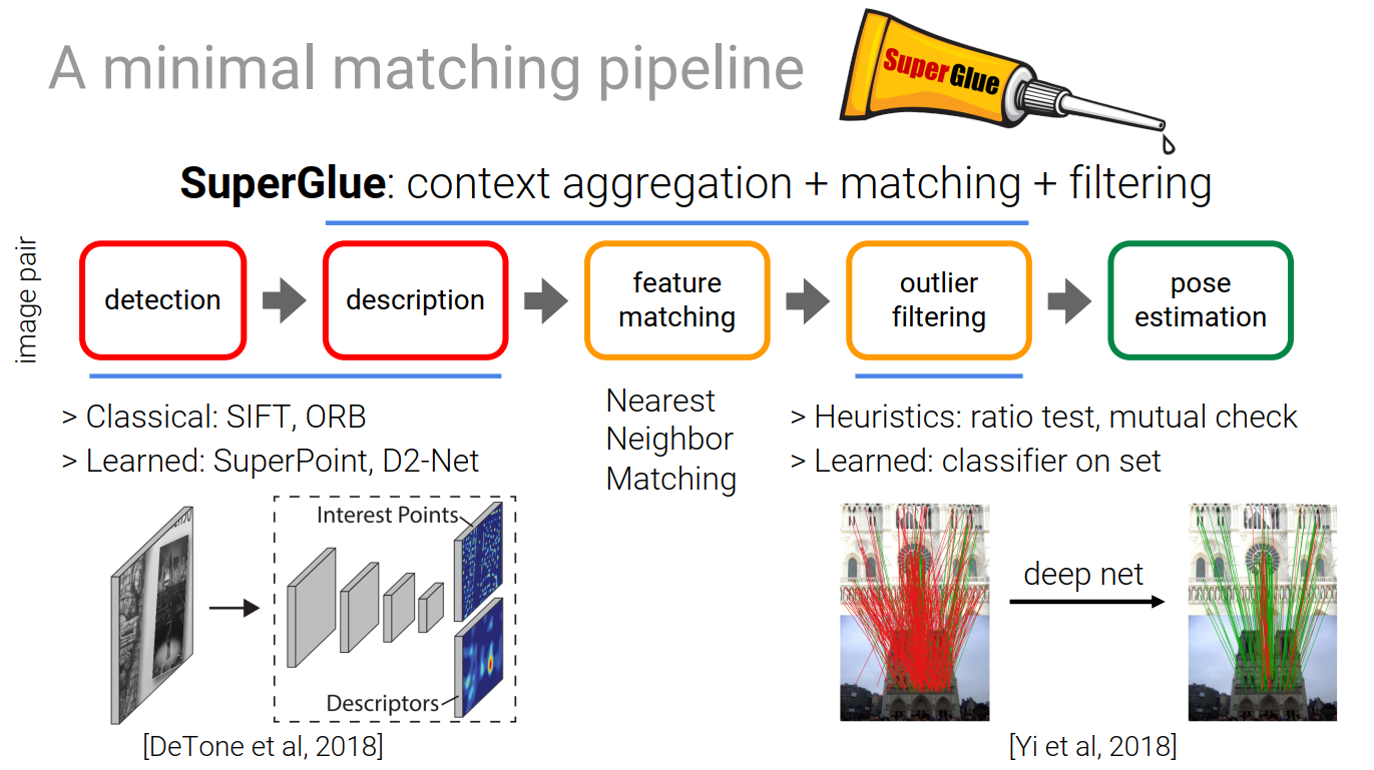 传统的特征可分5步走:1)提取特征点;2)计算描述子;3)最近邻匹配;4)滤除外点;5)求解几何约束;其中滤除外点一步包括点方法有:计算最优次优比,RANSAC,交叉验证以及neighborhood consensus。
传统的特征可分5步走:1)提取特征点;2)计算描述子;3)最近邻匹配;4)滤除外点;5)求解几何约束;其中滤除外点一步包括点方法有:计算最优次优比,RANSAC,交叉验证以及neighborhood consensus。
最近的一些工作主要集中在设计特异性更好的稀疏特征上,而它们的匹配算法仍然依赖于NN等策略:在做匹配时并没有考虑特征的结构相似性以及外观相似性。
图匹配
这类方法将特征的匹配问题描述成”quadratic assignment problems”,这是一个NP-hard问题,求解这类问题需要复杂不切实际的算子。后来的研究者将这个问题化简成”linear assignment problems”,但仅仅用了一个浅层模型,相比之下SuperGlue利用深度神经网络构建了一种合适的代价进行求解。此处需要说明的是图匹配问题可以认为是一种”optimal transport”问题,它是一种有效但简单的近似解的广义线性分配,即Sinkhorn算法。
深度点云匹配
点云匹配的目的是通过在元素之间聚集信息来设计置换等价或不变函数。一些算法同等的对待这些元素,还有一些算法主要关注于元素的局部坐标或者特征空间。注意力机制可以通过关注特定的元素和属性来实现全局以及依赖于数据的局部聚合,因而更加全面和灵活。SuperGlue借鉴了这种注意力机制。
框架以及原理
特征匹配必须满足的硬性要求是:
i)至多有1个匹配点;ii)有些点由于遮挡等原因并没有匹配点。
一个成熟的特征匹配模型应该做到:既能够找到特征之间的正确匹配,又可以鉴别错误匹配。
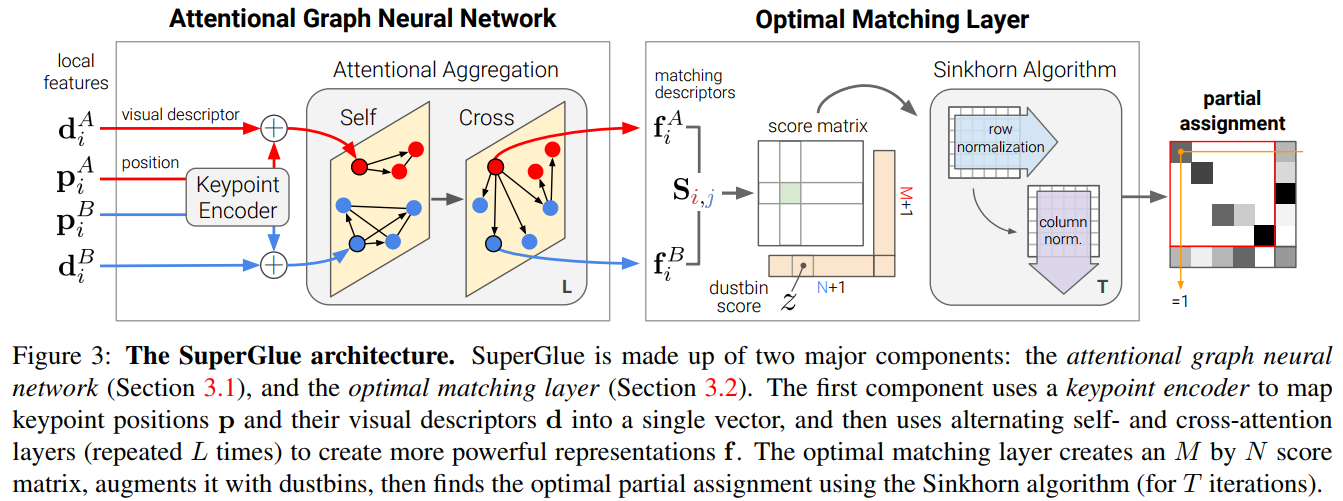
superglue_arch
整个框架由两个主要模块组成:注意力GNN以及最优匹配层。其中注意力GNN将特征点以及描述子编码成为一个向量(该向量可以理解为特征匹配向量),随后利用自我注意力以及交叉注意力来回增强(重复次)这个向量的特征匹配性能;随后进入最优匹配层,通过计算特征匹配向量的内积得到匹配度得分矩阵,然后通过Sinkhorn算法(迭代次)解算出最优特征分配矩阵。
公式化
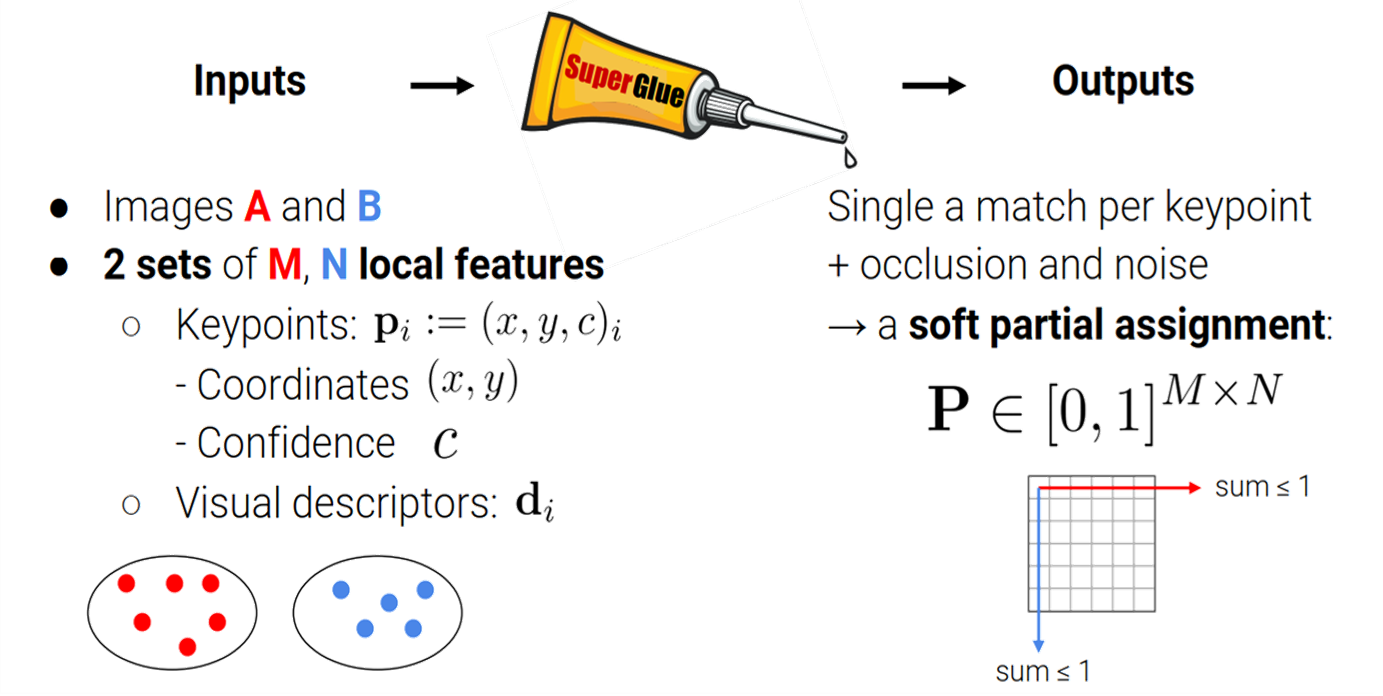 该部分对特征匹配问题建模。给定两张图片,每张图片上都有特征点位置以及对应的描述子,所以我们经常用来表示图像特征。第个特征可以表示为:
该部分对特征匹配问题建模。给定两张图片,每张图片上都有特征点位置以及对应的描述子,所以我们经常用来表示图像特征。第个特征可以表示为:
其中表示特征点提取置信度,表示特征坐标;描述子可以表示为:
其中表示特征维度,这里的特征可以是CNN特征,如SuperPoint,或者是传统特征SIFT。假设图像分别有个特征,可以表示为以及。
部分分配矩阵:约束i)和ii)意味着对应关系来自两组关键点之间的部分分配。我们给出一个软分配矩阵,根据上述约束,我们有如下关系:
但是我们在做优化问题时并不喜欢不等于,所以作者后续对得分矩阵以及对应的分配矩阵进行了增广,让上述约束变成了。具体地,我们放在遮挡以及可见性进行解释。
注意力GNN
这里有个有意思的说法:特征点的位置以及视觉外观能够提高其特异性。另外一个具有启发性的观点是人类在寻找匹配点过程是具有参考价值的。想一下人类是怎样进行特征匹配的,人类通过来回浏览两个图像试探性筛选匹配关键点,并进行来回检查(如果不是匹配的特征,观察一下周围有没有匹配的更好的点,直到找到匹配点/或没有匹配)。上述过程人们通过主动寻找上下文来增加特征点特异性,这样可以排除一些具有奇异性的匹配。本文的核心就是利用基于注意力机制的GNN实现上述过程,即模拟了人类进行特征匹配。
特征点Encode
特征点编码代码如下:
将描述子与编码后的特征点相加可以得到后续多层GNN的输入的初值:
desc0 = desc0 + self.kenc(kpts0, data['scores0']) #图A
desc1 = desc1 + self.kenc(kpts1, data['scores1']) #图B多层GNN
需要说明的是,这里的self-/cross-attention实际上就是模拟了人类来回浏览匹配的过程,其中self-attention是为了使得特征更加具有匹配特异性,而cross-attention是为了用这些具有特异性的点做图像间特征的相似度比较。
代码如下:
这一小节介绍上述介绍种的message是如何获得的。
这里需要解释一下键(key),query以及值(value)。令待查询点特征点位于查询图像上,所有的源特征点位于图像上,其中。上面提到的这些概念有些难以理解,作者特意对上述过程进行了可视化,self-attention就是一张图像内部的边相连进行聚合,它能够更加关注具有特异性的所有点,且并不仅局限于其邻域位置特征(心心相依,何惧千里,逃…);cross-attention做的就是匹配那些外观相似的两张图像见的特征。
匹配层(Optimal matching layer)
匹配得分预测
为何上式中使用 "" 而非 ""?这里值得说明一下。
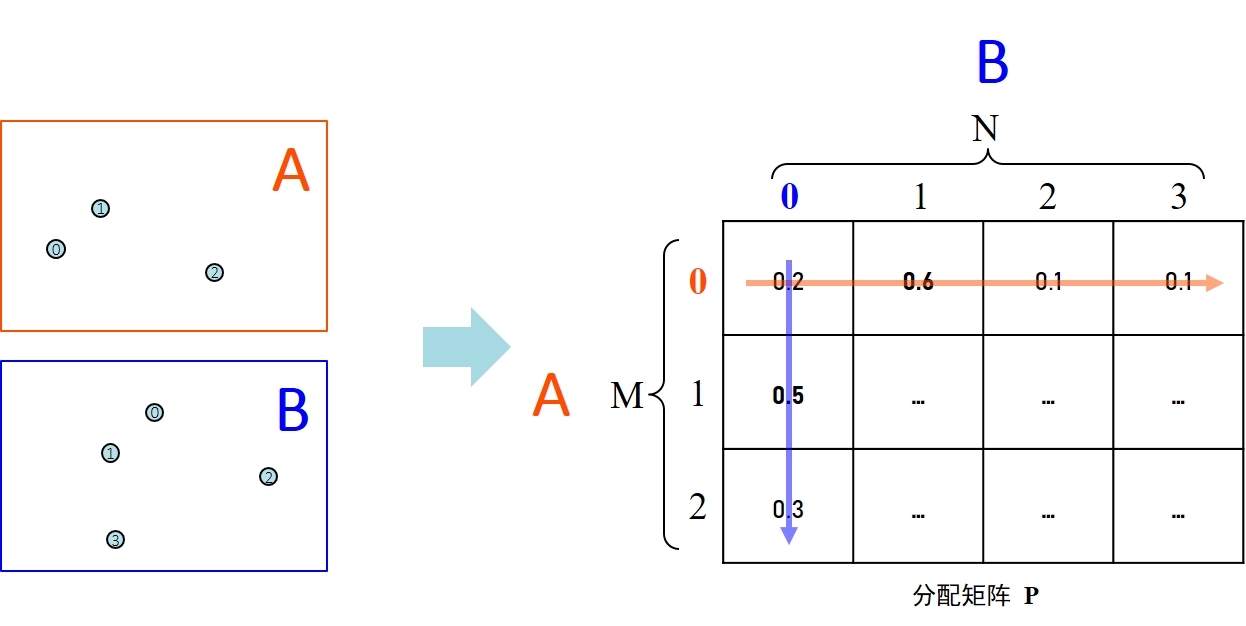
首先要理解分配矩阵是什么。的每一行代表来自于图中的某个特征点对应图的种匹配的可能性。如上图所示,图有3个特征点,图有4个特征点,那么这个分配矩阵的维度就是。对于第0行,即图A的第0号特征点,它可能在图B中有4个匹配点,由上图种给出的软分配矩阵的第0行数据可以看到,最大是数字是0.6,即图的第0号特征与图B的第1号特征是匹配的。相应的,对于的第0列,最大是数字是0.5,即图的第0号特征与图的第1号特征是匹配的,这看起来非常合理。
这里需要注意的是,这个是一个所谓的”软分配”矩阵,所以其中的元素并非是绝对的0或1。对于还需要满足规定:在理想情况下的行之和或者列之和等于1。此处的”理想情况”指的是图与图中的所有特征都可以在对方的图像上找到对应关系。但是实际情况下,可能存在遮挡/视角变化/检测噪声等因素的干扰,大概率会出现图在图中找不到对应的匹配点,反之亦然。
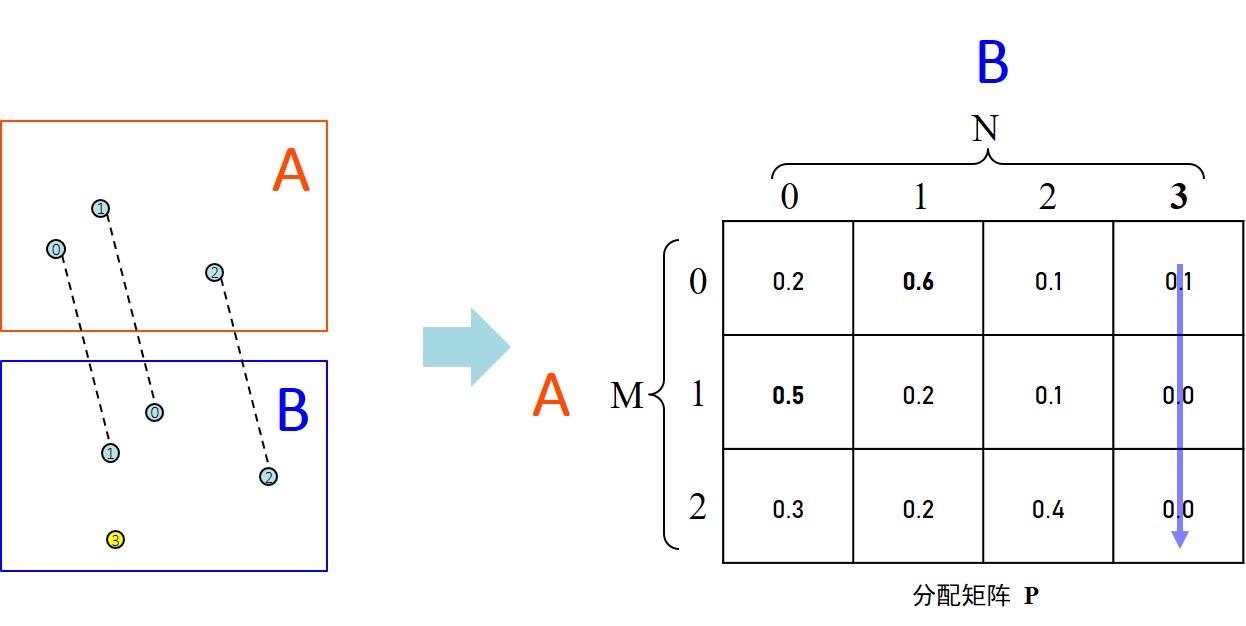
如上图所示,对于的第3列,即图的第3号特征而言,它并没有找到于其对应的特征匹配,所以对应的第3列之和是小于1的,确切来说对于一个调校的特别好的网络而言,第3列之和接近于0。
那后续设计网络的最终目标就是解算构建一个代价矩阵并这个分配矩阵。
首先根据上述说法,特征点位置+描述会获得更强的特征匹配特异性,所以这里将特征点的位置以及描述子合并成每个特征点的初始表示:
其中MLP表示多层感知机(Multilayer Perceptron,MLP)此处用于对低维特征升维,上式实际上是将视觉外观以及特征点位置进行了耦合,正因如此,这使得该Encode形式使得后续的注意力机制能够充分考虑到特征的外观以及位置相似度。
class KeypointEncoder(nn.Module):
""" Joint encoding of visual appearance and location using MLPs"""
""" feature_dim: 256, layers: [32, 64, 128, 256]"""
def __init__(self, feature_dim, layers):
super().__init__()
self.encoder = MLP([3] + layers + [feature_dim]) # MLP([3, 32, 64, 128, 256, 256])
nn.init.constant_(self.encoder[-1].bias, 0.0)
def forward(self, kpts, scores):
inputs = [kpts.transpose(1, 2), scores.unsqueeze(1)]
return self.encoder(torch.cat(inputs, dim=1)) # DIM: 1x256xM
def MLP(channels: list, do_bn=True):
""" Multi-layer perceptron """
n = len(channels)
layers = []
for i in range(1, n):
layers.append(
nn.Conv1d(channels[i - 1], channels[i], kernel_size=1, bias=True))
if i < (n-1):
if do_bn:
layers.append(nn.BatchNorm1d(channels[i]))
layers.append(nn.ReLU())
return nn.Sequential(*layers)# Keypoint MLP encoder.考虑一个单一的完全图,它的节点是图像中每个特征点,这个图包括两种不同的无向边:一种是”Intra-image edges”(self edge),它连接了来自图像内部特征点;另外一种是”Inter-image edges”(cross edge),它连接本图特征点与另外一张图所有特征点(构成了该边)。
令表示为图像上第个元素在第层的中间表达形式。信息(message)是聚合了所有特征点之后点结果(它的具体形式后面的Attentional Aggregation会介绍,一句话来说就是将自我注意力以及交叉注意力进行聚合),其中,所以图像中所有特征传递更新的残差信息是:
其中表示串联操作。同样的,图像上所有特征有类似的更新形式。可以看到self 以及cross edges绑在一起并交替进行更新,先self后cross,作者提到共有固定数量的层。
class AttentionalGNN(nn.Module):
def __init__(self, feature_dim: int, layer_names: list):
super().__init__()
self.layers = nn.ModuleList([
AttentionalPropagation(feature_dim, 4)
for _ in range(len(layer_names))])
self.names = layer_names
def forward(self, desc0, desc1):
for layer, name in zip(self.layers, self.names):
layer.attn.prob = []
if name == 'cross':
src0, src1 = desc1, desc0
else: # if name == 'self':
src0, src1 = desc0, desc1
delta0, delta1 = layer(desc0, src0), layer(desc1, src1)
desc0, desc1 = (desc0 + delta0), (desc1 + delta1)
return desc0, desc1
class AttentionalPropagation(nn.Module):
def __init__(self, feature_dim: int, num_heads: int):
super().__init__()
self.attn = MultiHeadedAttention(num_heads, feature_dim)
nn.init.constant_(self.mlp[-1].bias, 0.0)
def forward(self, x, source):
message = self.attn(x, source, source) # q,k,v, DIM: 1x256xM
return self.mlp(torch.cat([x, message], dim=1)) #DIM: 1x256xMAttentional Aggregation



self.mlp = MLP([feature_dim*2, feature_dim*2, feature_dim]) #其中MLP隐含层配置[512,512,256]文章的亮点之一就是将注意力机制用于特征匹配,这到底是如何实现的呢?作者提到,注意力机制将self以及cross信息聚合得到。其中self edge利用了self-attention,cross edge利用了cross-attention。类似于数据库检索,我们想要查询基于元素的属性即键,检索到了某些元素的值。
其中注意力权重是查询与检索到对象键值相似度的即:
于是我们可以将key,query以及value写成下述形式:
每一层都有其对应的一套投影参数,这些参数被所有的特征点共享。理解一下:此处的对应于待查询图像上某个特征点的一种表示(self-attention映射),以及都是来自于召回的图像特征点的一种表示(映射);表示这两个特征相似度,它是由以及计算得到(在这里体现了cross-attention的思想?),越大就表示这两个特征越相似,然后利用该相似度对加权求和得到,这就是所谓的特征聚合。
下图展示了每层self-attention以及across-attention中权重的结果。按照匹配从难到易,文中画出了3个不同的特征点作为演示,绿色特征点(容易),蓝色特征点(中等)以及红色特征点(困难)。对于self-attention,初始时它(某个特征)关联了图像上所有的点(首行),然后逐渐地关注在与该特征相邻近的特征点(尾行)。同样地,cross-attention主要关注去匹配可能的特征点,随着层的增加,它逐渐减少匹配点集直到收敛。绿色特征点在第9层就已经趋近收敛,而红色特征直到最后才能趋紧收敛(匹配)。可以看到无论是self还是cross,它们关注的区域都会随着网络层深度的增加而逐渐缩小。
经过了次self/cross-attention后就可以得到注意力GNN的输出,对于图像我们有:
我们可以把理解为匹配描述子(类比特征描述子),专门为特征匹配服务,对于图像具有类似的形式。
接下来的任务就是去构建软分配矩阵。对于一般的图匹配流程,这个分配矩阵可以通过计算一个得分矩阵(用来表示一些潜在的匹配)来实现。具体而言,通过最大化总体得分即可得到这个分配矩阵,其中要注意的是是有约束的。
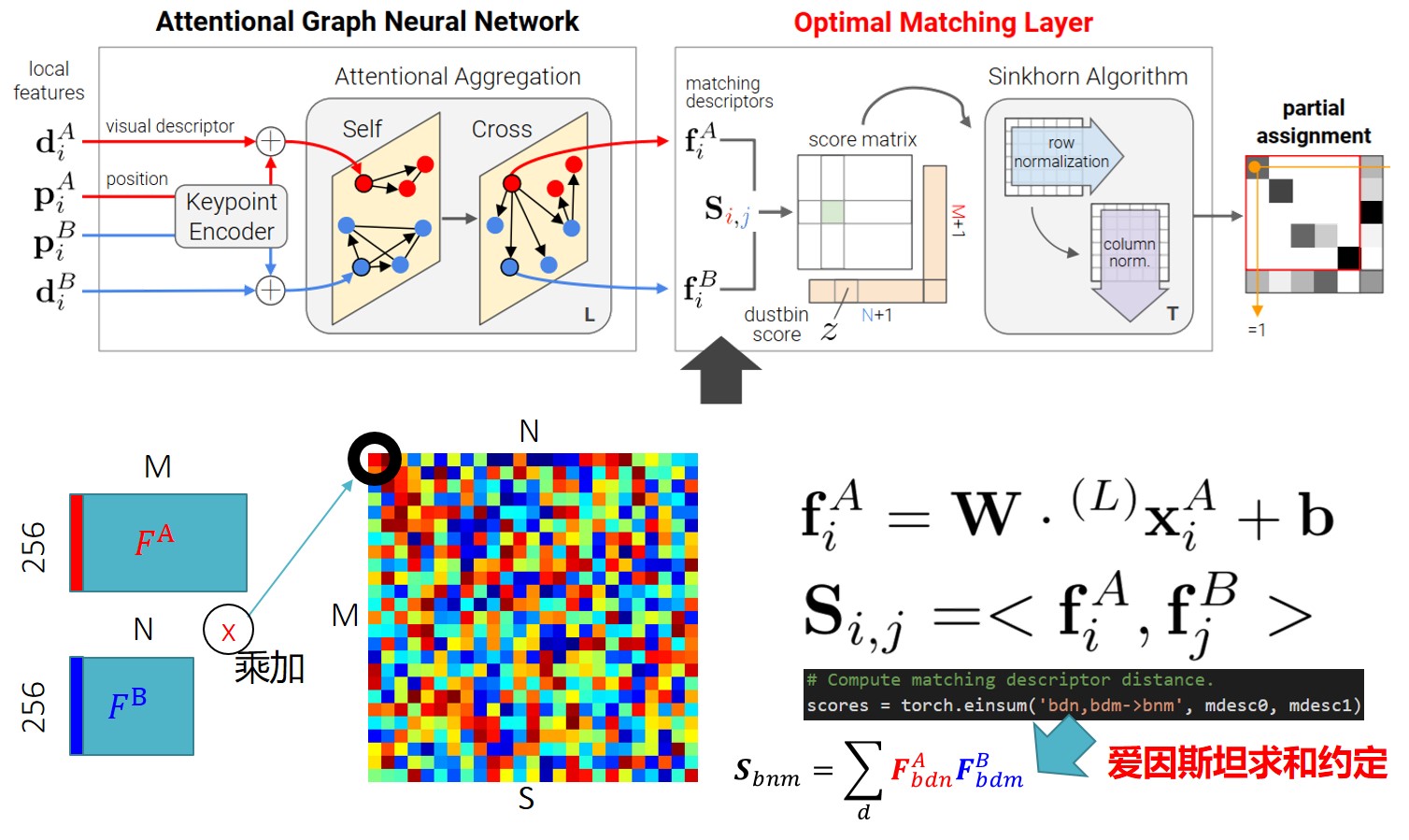
作者使用GNN聚合得到的以及计算内积得到得分。
遮挡以及可见性
类似于SuperPoint在提取特征点时增加了一层dustbin通道,专门为了应对图像中没有特征点情况。本文借鉴了该思想,在得分矩阵的最后一列/行设置为dustbins可以得到,这样做的作用在于可以滤出错误的匹配点。
图像上的特征点被分配到图像上某个特征匹配或者被分配到dustbin,这就意味着每个dustbin有个匹配,因此软分配矩阵有如下约束:
其中:
表示图中特征点以及dustbin的期望匹配数,即正常情况下,图中每个特征点在图中仅且仅有1个匹配点,但是对于图的dustbin而言,它可能匹配到图B的任何一个特征点,即有种可能性。
作者Sarlin在这个问题中提到,上式的约束项之所以被替换成,是因为做了类似于松弛化的操作,这么做的好处是将原本难以优化的不等问题变为恒等约束(原话为”These are like slack variables that enforce the equality constraint”),同时可以比较好的应对没有匹配的特征或者错误的特征(这其实是增加dustbin通道的原因,它起到滤除外点的作用)。
Sinkhorn Algorithm

clear all;
close all;
clc;
lam = 1;
epslion = 1e-6;
S = [1,2,3,4;
5,6,7,8;
2,6,1,3];
[m,n] = size(S);
a = ones(m,1);
b = ones(1,n);
[P_bar, error] = SinkhornAlgorithm(S,a,b,lam,epslion);
figure;
axis equal
imagesc(P_bar)
set(gcf,'color',[1,1,1]);
box off;
axis off
function [P_bar, error] = SinkhornAlgorithm(S,a,b,lam,epslion)
% add dustbin channel
dust= 5;
[m,n] = size(S);
S_bar = [S,dust * ones(m,1);
dust *ones(1,n+1)];
a = [a;n];
b = [b,m];
%% OT BEGIN
[m,n] = size(S_bar);
P_bar = exp(-lam * S_bar);
P_bar = P_bar / sum(P_bar(:));
max_iters = 100;
counter = 0;
while 1
u = sum(P_bar,2); % sum of rows
P_bar = P_bar .* repmat(a./ u,[1,n]); % scale rows
v = sum(P_bar,1); % sum of cols
P_bar = P_bar .* repmat(b./ v,[m,1]); % scale cols
error = max((sum(P_bar,2) - a)); % check error
disp(['error = ', num2str(error)]);
if(error < epslion || counter > max_iters)
break;
end
counter = counter + 1;
end
end %end functiondef log_optimal_transport(scores: torch.Tensor, alpha: torch.Tensor, iters: int) -> torch.Tensor:
""" Perform Differentiable Optimal Transport in Log-space for stability"""
b, m, n = scores.shape
one = scores.new_tensor(1)
ms, ns = (m*one).to(scores), (n*one).to(scores)
bins0 = alpha.expand(b, m, 1)
bins1 = alpha.expand(b, 1, n)
alpha = alpha.expand(b, 1, 1)
couplings = torch.cat([torch.cat([scores, bins0], -1),
torch.cat([bins1, alpha], -1)], 1)
norm = - (ms + ns).log()
log_mu = torch.cat([norm.expand(m), ns.log()[None] + norm])
log_nu = torch.cat([norm.expand(n), ms.log()[None] + norm])
log_mu, log_nu = log_mu[None].expand(b, -1), log_nu[None].expand(b, -1)
Z = log_sinkhorn_iterations(couplings, log_mu, log_nu, iters)
Z = Z - norm # multiply probabilities by M+N
return Z
def log_sinkhorn_iterations(Z, log_mu, log_nu, iters: int):
""" Perform Sinkhorn Normalization in Log-space for stability"""
u, v = torch.zeros_like(log_mu), torch.zeros_like(log_nu)
for _ in range(iters):
u = log_mu - torch.logsumexp(Z + v.unsqueeze(1), dim=2)
v = log_nu - torch.logsumexp(Z + u.unsqueeze(2), dim=1)
return Z + u.unsqueeze(2) + v.unsqueeze(1)Loss
GNN网络以及最优匹配层都是可微的,这使得反向传播训练成为可能。网络训练使用了一种监督学习的方式,即有了匹配的真值,当然也可以获得一些没有匹配的特征点以及。当给定真值标签,就可以去最小化分配矩阵的负对数似然函数:
superglue_tb_1
superglue_tb_2
superglue_tb_3
superglue_tb_3


(此处不太理解,最后一维为何为N?此处可参考这篇文章的解释。)
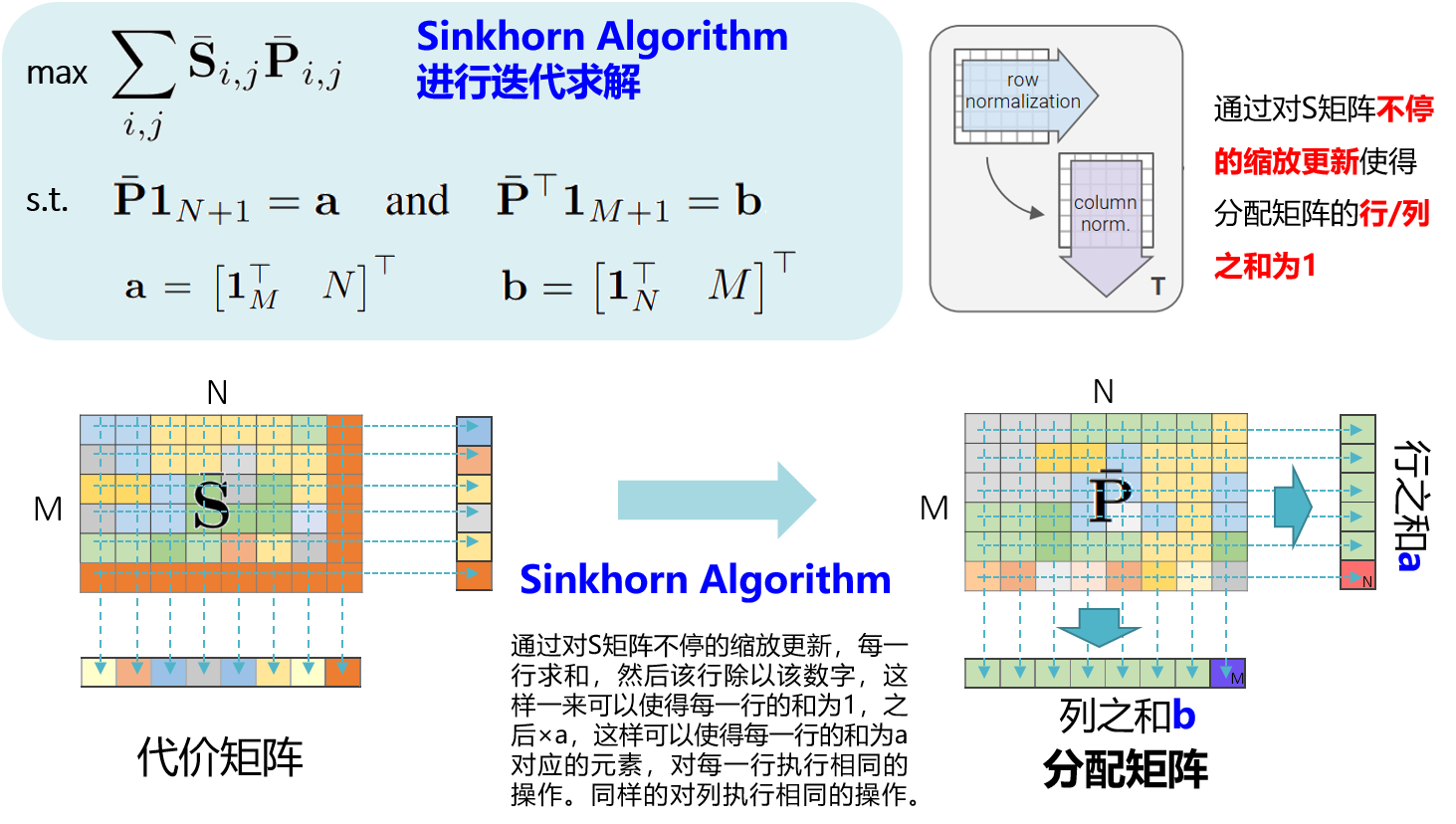
求解最大化总体得分可由”Sinkhorn Algorithm”进行求解。
此处有必要对optimal transport问题做一下解释,有关optimal transport问题的介绍可参考这篇文章Notes on Optimal Transport。如上图所示,蓝色背景区域的几个公式给出了针对该特征匹配问题的”代价函数”,准确来说应该是负的代价函数。因为原始的最优传输问题中扮演的角色应该是cost matrix,即代价矩阵;对比之下,本例中为匹配描述子的余弦相似度,这正好与代价矩阵相反。正因如此,相较于原始最优传输问题的最小化代价函数,本例的目标是最大化匹配描述子的相似度,所以上式为而非。
至于如何求解最优传输问题,sinkhorn algorithm算法能够以一种迭代的方式对该问题进行求解,具体的方法是:
给定:匹配描述子的余弦相似度矩阵,两个分布和,正则项(越大表示分配越均匀,默认为1)
初始化:分配矩阵
重复:
- 缩放行,使得行之和为
- 缩放列,使得列之和为
直至收敛.
接下来,笔者给出一个简单的例子,一步步阐述sinkhorn algorithm是如何运作的。
首先给定输入,并初始化分配矩阵(注,为方便起见,分配矩阵被初始化为代价矩阵,实际情况下是)。
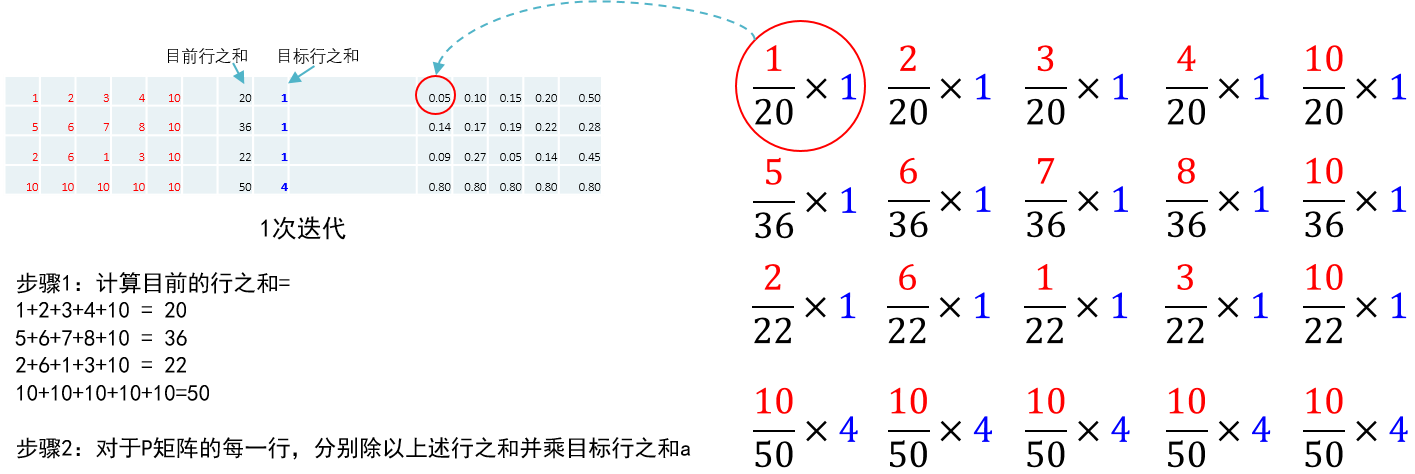
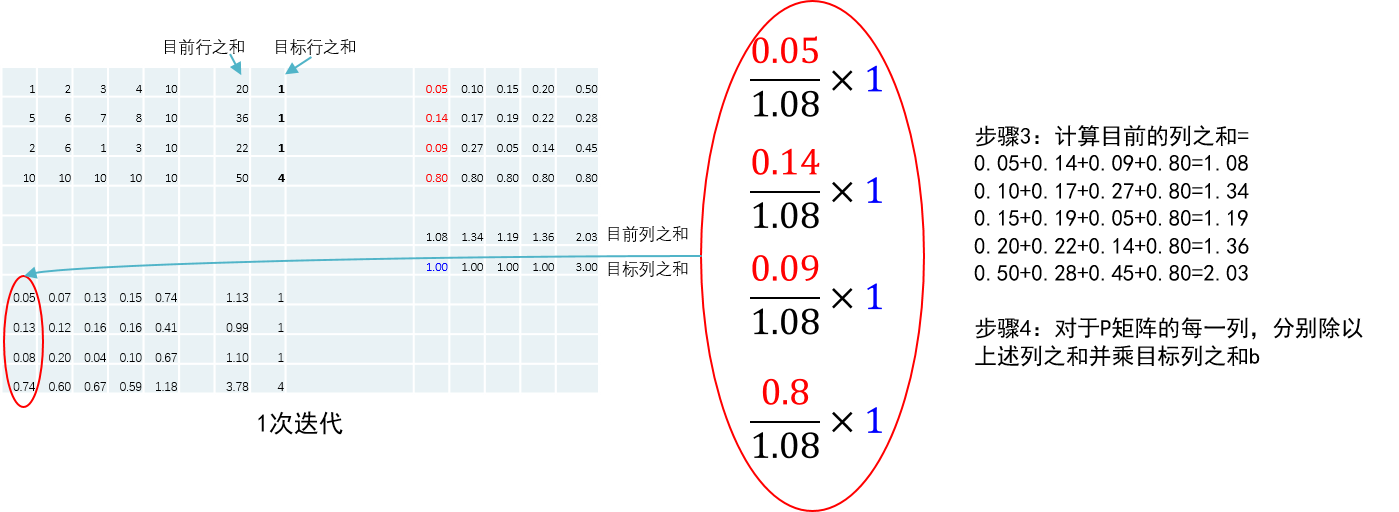
步骤1:计算目前的行之和;步骤2:对于P矩阵的每一行,分别除以上述行之和并乘目标行之和a;步骤3:计算目前的列之和;步骤4:对于P矩阵的每一列,分别除以上述列之和并乘目标列之和b;对行列重复执行1-4步,经过4次迭代后分配矩阵的行之和就与一致,列之和与一致。
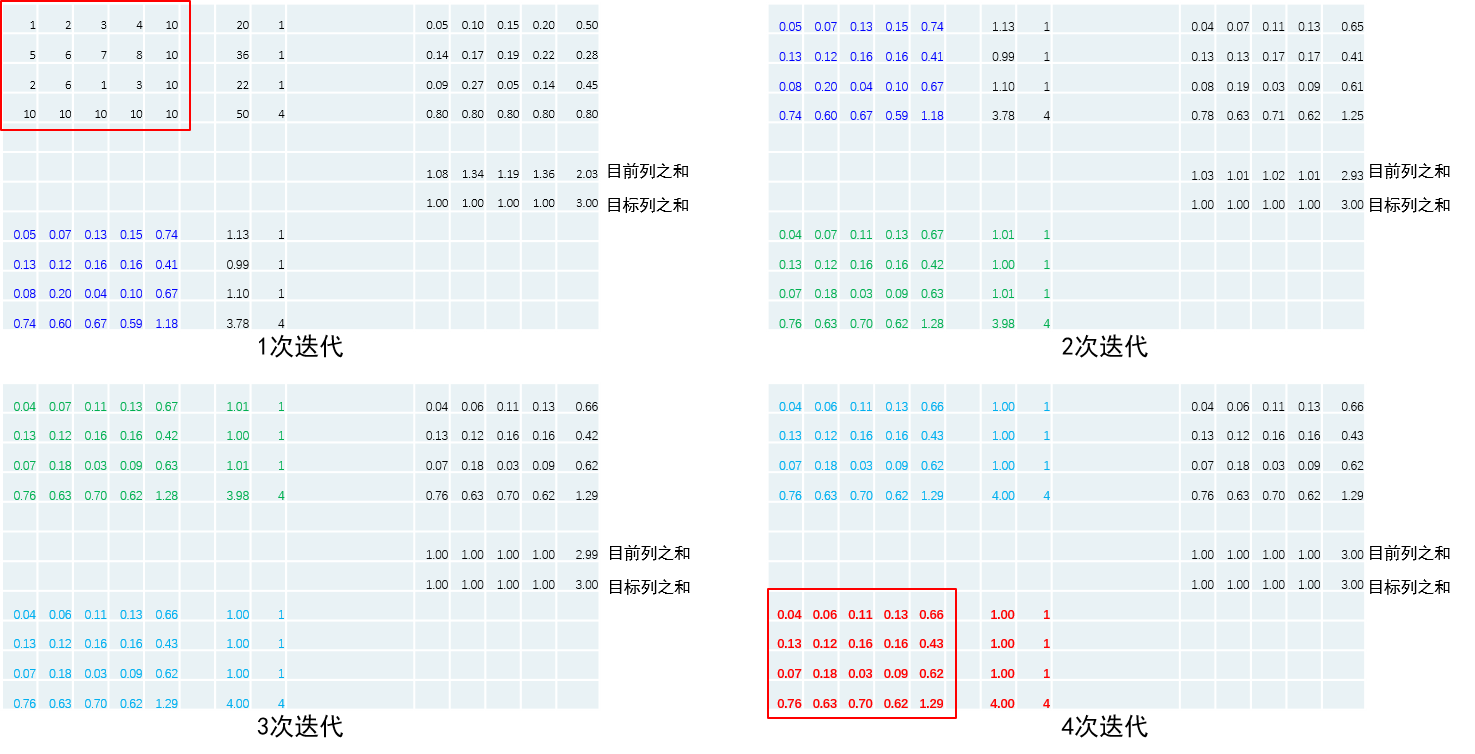
下面笔者使用matlab重写了一个sinkhorn algorithm的demo,感兴趣的同学可以运行一下,然后check下最后的分配矩阵P的行之和是否为1/列之和是否为1。
值得注意的是作者采用对数空间的sinkhorn algorithm算法,所以在完成算法迭代之后需要对结果进行指数运算才能得到分配矩阵。
作者Sarlin提供的代码如下:
这个监督学习的目标是同时最大化精度以及匹配的召回率,接下来的训练过程略过,直接开始实验阶段的介绍。
实验
特征匹配的目的是为了解算出两帧之间的相对位姿,所以实验对比的一个指标就是单应矩阵估计,另外还有室内外的位姿估计。只能说SuperGlue的效果太好了,直接放结果吧(本来论文7页就写完了,作者放了10页附录大招)。
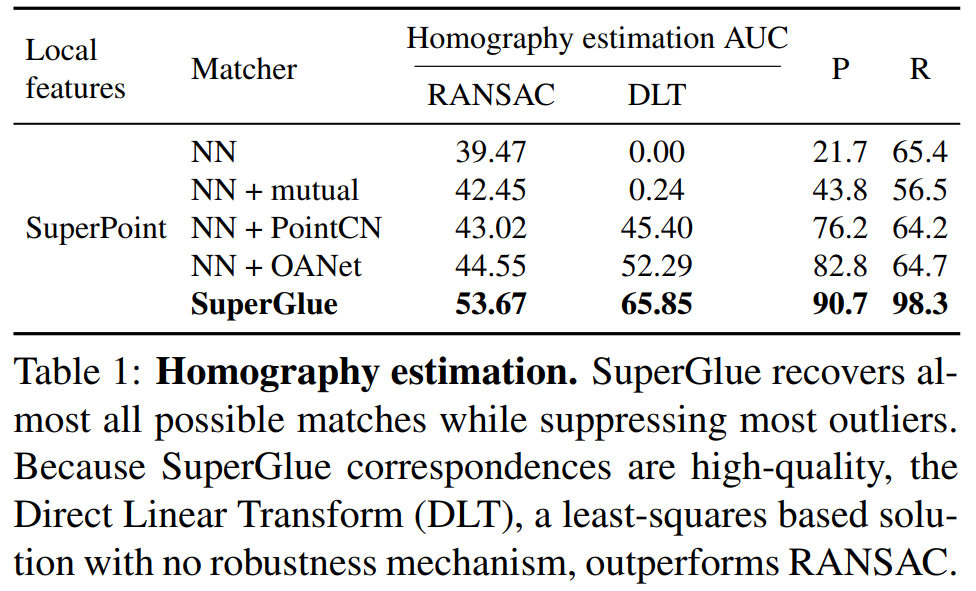
单应矩阵估计
能够获得非常高的匹配召回率(98.3%)同时获得超高的精度,比传统的暴力匹配都好了一大截。
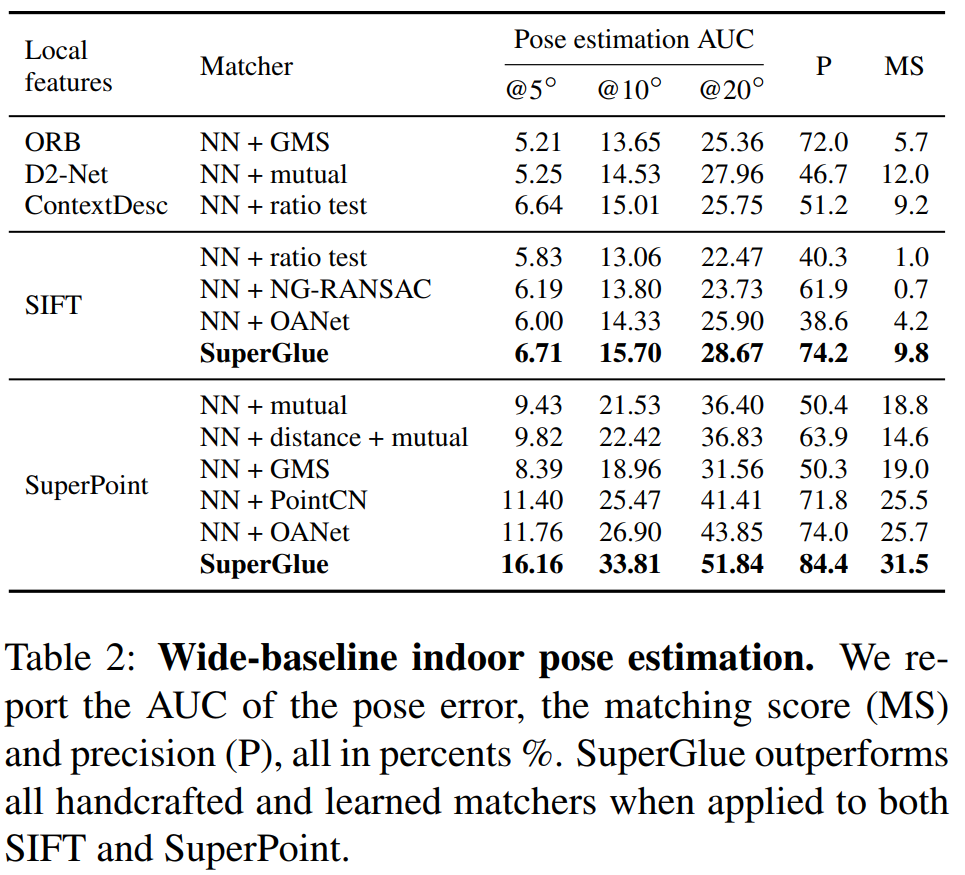
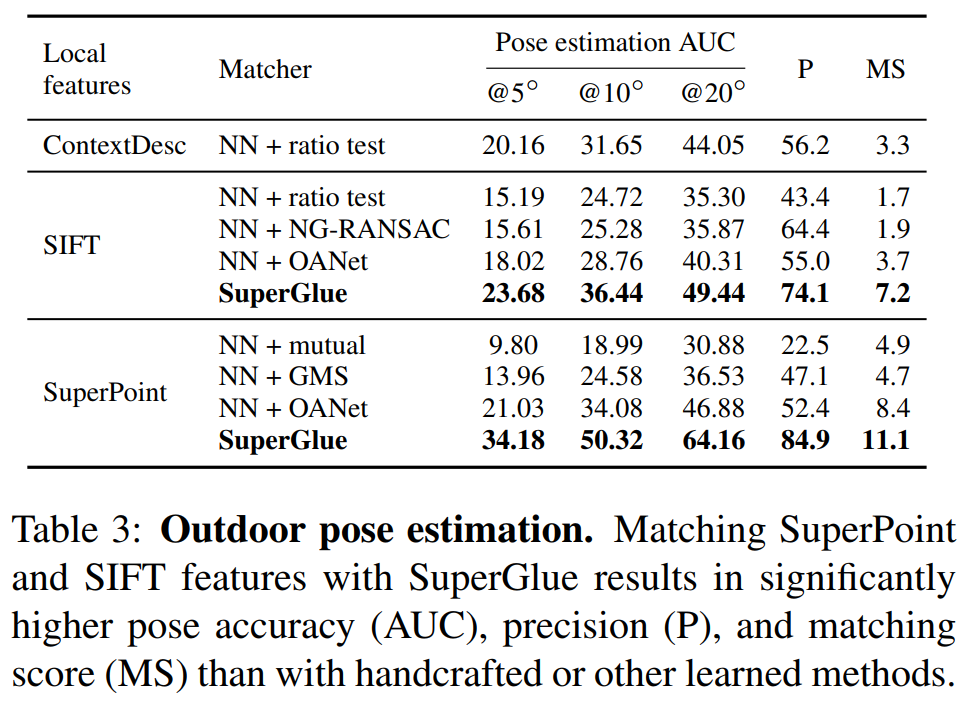
室内外位姿估计
下表看来,大基线室内位姿估计也是相当棒,完胜传统算法。
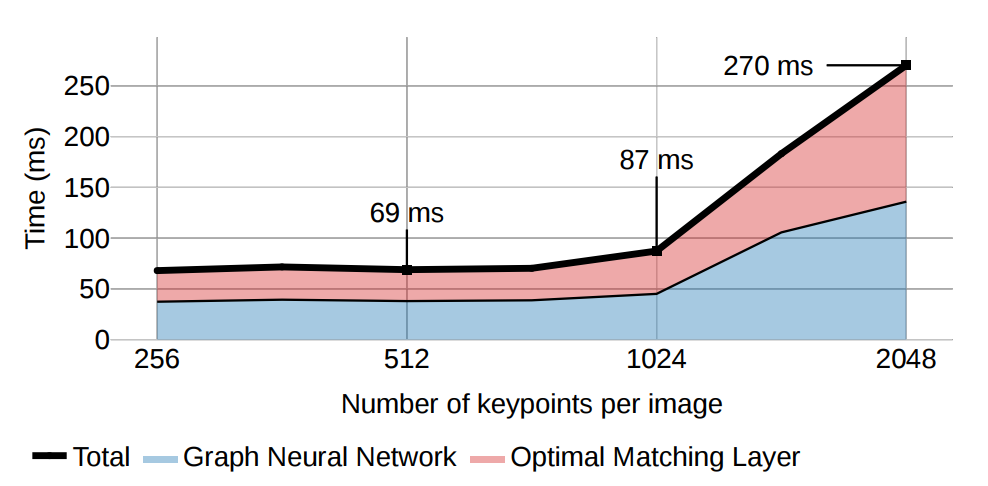
网络耗时
接下来放出大家比较关心的网络耗时,下图是在NVIDIA GeForce GTX 1080 GPU跑了500次的结果,512个点69ms(14.5fps),1024个点87ms(11.5fps)。
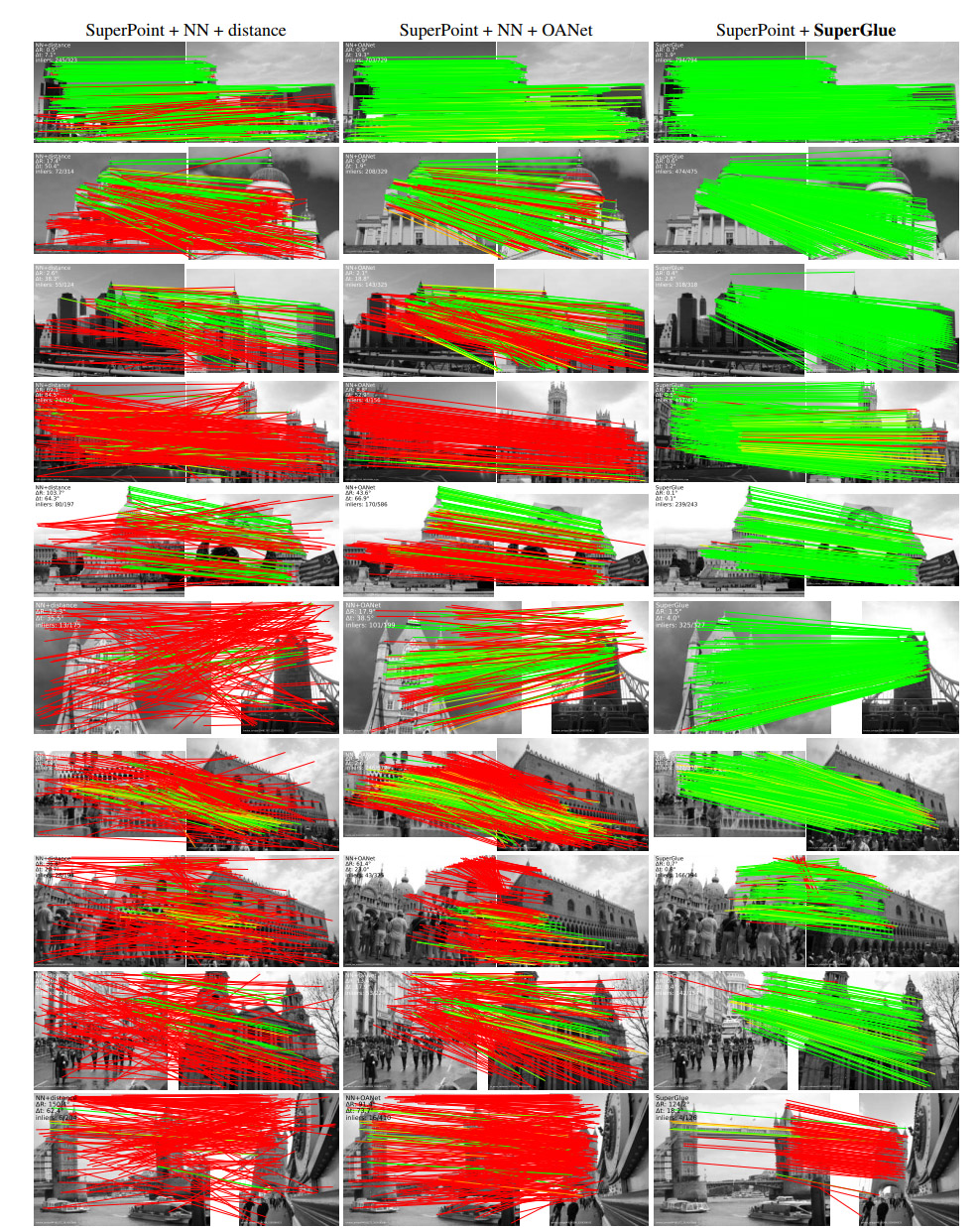
更多匹配结果
第一列是SuperPoint+暴力匹配结果,第二列是SuperPoint+OAnet(ICCV 2019)结果,第三列是SuperPoint+SuperGlue结果。能看到SuperGlue惊人的特征匹配能力,尤其是在大视角变化时优势明显(红线表示错误匹配,绿线表示正确匹配)。
结论
本文展示了基于注意力的图神经网络对局部特征匹配的强大功能。 SuperGlue的框架使用两种注意力:(i)自我注意力,可以增强局部描述符的接受力;以及(ii)交叉注意力,可以实现跨图像交流,并受到人类来回观察方式的启发进行匹配图像。文中方法通过解决最优运输问题,优雅地处理了特征分配问题以及遮挡点。实验表明,SuperGlue与现有方法相比有了显着改进,可以在极宽的基线室内和室外图像对上进行高精度的相对姿势估计。此外,SuperGlue可以实时运行,并且可以同时使用经典和深度学习特征。
总而言之,论文提出的可学习的中后端(middle-end)算法以功能强大的神经网络模型替代了手工启发式技术,该模型同时在单个统一体系结构中执行上下文聚合,匹配和过滤外点。作者最后提到:若与深度学习前端结合使用,SuperGlue是迈向端到端深度学习SLAM的重要里程碑。(when combined with a deep front-end, SuperGlue is a major milestone towards end-to-end deep SLAM)
这真是鼓舞SLAM研究人员的士气!
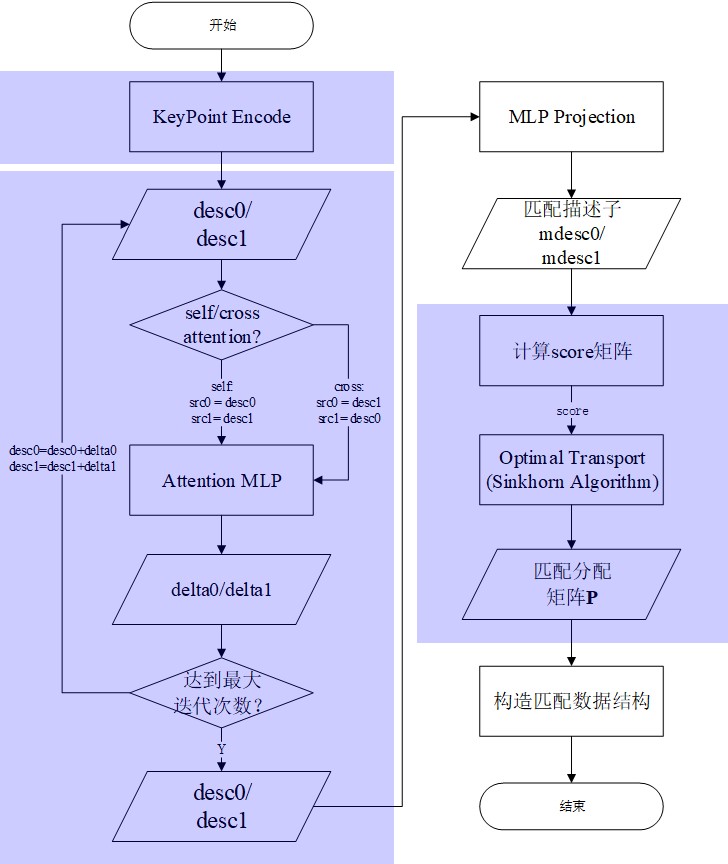
顺便给个SuperGlue代码的流程框图:
改进点 (Update: 2022.05.17)
主要从改进特征编码形式,attention形式,改进最优传输问题的求解策略等角度进行展开。
- A Unified Framework for Implicit Sinkhorn Differentiation,CVPR 2022,分析了深度学习中任务中通用
Sinkhorn层的隐含梯度的使用,文中指出SuperGlue中使用的是自动微分的sinkhorn algorithm,收敛速度可能较慢且容易出现OOM,而本算法能够解决该问题(不过并没有进行验证) [Code] - OpenGlue - Open Source Pipeline for Image Matching,arXiv 2022,复现了SuperGlue,包括训练以及推理过程,OpenGlue对基于图的匹配过程进行概况,形成了一套易替换和后续开发的模块和流程;此外基于上述流程对SuperGlue中attention等步骤进行改进;开源协议有更新,OpenGlue可商用 [Code]
- MatchFormer: Interleaving Attention in Transformers for Feature Matching,arXiv 2022,改进的LoFTR, 将attention引入特征编码阶段,大幅度提升特征匹配在大视角变化时的匹配性能 [Code]
- LoFTR: Detector-Free Local Feature Matching with Transformers, CVPR 2021,无特征匹配,匹配性能强劲 [Code]
- valgur/SuperGluePretrainedNetwork, 实现了 C++ 调用 SuperGlue:包含使用 jit scripts 将SuperPoint以及SuperGlue序列化,然后使用pytorch的 C++ 接口进行调用 [Code]
- SuperGlue with Physarum Dynamics, 最优传输问题的求解由Sinkhorn Algorithm 替换成 Physarum Dynamics solver [Code]
- Superglue-Jittor,改进了图注意力机制中矩阵运算,采用分块优化的方式进行,降低了匹配过程中的显存占用;使用
dual-Softmax替换sinkhorn algorithm[Code] - SuperGlue PyTorch Implementation,pytorch复现SuperGlue [Code]
- MNNSuperGlue,MNN Superglue 关键点匹配C++实现 [Code]